構造化データと非構造化データとは?
活用の難しさと解決手法
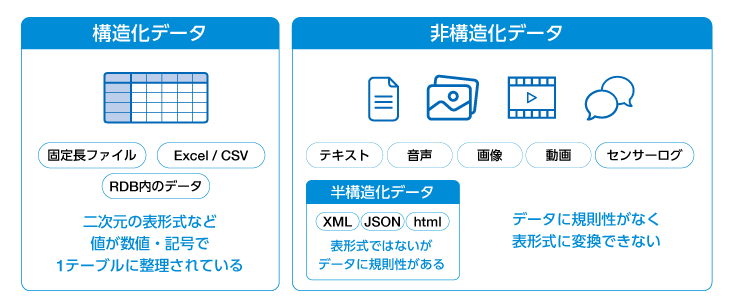
構造化データとは「列」と「行」の概念をもつデータのことで、非構造化データとは構造定義されていないデータのことを指します。
企業のDX(デジタルトランスフォーメーション)、デジタル戦略において近年、ユーザーニーズに即した商品開発やLTV(ライフタイムバリュー:顧客生涯価値)の向上、ITによる業務効率化などを目的として、特に非構造化データの分析・活用の重要性が高まっています。CDPを活用する際には押さえるべき設計視点の一つです。
今回は「構造化データ、非構造化データとは何か」「それぞれ何が違うのか」「非構造化データの活用がなぜ重要で、なぜ活用が難しいのか」を紐解き、「どうすれば非構造化データが活用可能になるのか」をTOPPANのサポート領域も含めて解説します。

あらゆるデータを統合・管理し、CDP/DMP構築・運用を成功へと導く
TOPPANのデータエキスパート陣

多業種の知見を活かし、顧客の「やりたい」を実現
【データエンジニア】 河口 達男
入社以来IT部門にて様々な業種のWebシステム構築やアプリ開発を担当し、システム開発の知識/経験を習得。
2017年よりCDP/MAの構築および運用・拡張を担当。
●所有資格●
・Treasure Data Certified Project Leader
データを価値に変える、戦略的アーキテクト
【データエンジニア】 下村 勇介
2011年入社時は、社内情報システム部門にて業務システム開発・DB設計(Oracle)を担当。
2018年よりデジタルマーケティング領域にてデータエンジニアとしてTreasure Data CDPやパブリッククラウドを活用したデジタルマーケティング基盤構築・運用を担当。
●所有資格●
・Treasure Data Certified Engineer
・Google Cloud Certified Professional Data Engineer
・Google Cloud Certified Professional Cloud Architect

透明性の高い技術と、嘘のない対話
【データエンジニア】 甲州 美加
2014年入社以来、教育関連のシステム開発運用を経験し、2021年にCDPの開発運用案件に参画。
以降さまざまなクライアントのデジタルマーケティング基盤の構築、運用の伴走型での支援に従事。
●所有資格●
・Salesforce 認定 Data Cloud コンサルタント
・Treasure Data Certified Project Leader
<目次>
1.構造化データとは?
2.非構造化データとは?
3.半構造化データとは?
4.構造化・非構造化データの違い
5.非構造化データの活用はなぜ重要?難しい理由は?
6.非構造化データを活用するには
7.データ活用における「データレイク」と「DWH」とは
8.非構造化データの「適切な管理」という課題
9.まとめ
10.その他構造化データに関するよくある質問
1.構造化データとは?
構造化データとは、ExcelやCSVファイルに代表される、「列」と「行」の概念をもつデータのことです。文字通り「構造化」されているため検索、集計や比較などが行いやすく、データの解析や分析に最も適したデータ構造です。ERP、CRMなどの業務システムでデータを効率よく管理するRDB(リレーショナル・データベース)でも用いられます。
例)CSV、固定長、Excel(リレーショナルデータベース形式)
構造化データのメリット
構造化データは、効率的な検索とデータの再利用が可能であることがメリットといえます。
前述の通り「列」と「行」の概念を有するということは、フィールドが定められ、データが整理されることになります。それにより、効率的に検索できるほか、データの操作やクエリの実行が行いやすく、それらを繰り返し行うことができます。また、データの整合性を保ちやすく、エラーの発生が少ないのも大きな利点です。
構造化データのデメリット
一方で、構造化データは目的以外での利用が困難という柔軟性の欠如が挙げられます。事前に定義されたデータは、その意図による目的でしか利用できません。もし目的や要件に変更が発生した場合、すべての構造化データの更新が必要となるケースが多く、膨大な時間とリソースを投下することになります。
2.非構造化データとは?
非構造化データとは、その名の通り構造定義されていないデータのことを指します。データベース化ができないため、検索や集計、解析に不向きなデータです。eメール、提案書・企画書、見積書・発注書、契約書などのOffice文章、デザインデータ、CADデータ、画像、動画、音声、センサーログなど、日常の業務で生成されるさまざまなデータが含まれます。データ単体で意味を持ち、用途も異なるうえに量が多く、発生する頻度も高いのが特徴です。
*データ内に規則性に関する区切りはあるものの、データの一部を見ただけでは二次元の表形式(Excel形式)への変換可能性、変換方法が分からないXML、jsonなどの「半構造化データ」も含まれます。
例)規則性に関する区切りのないテキスト、PDF、音声、画像、動画
非構造化データのメリット
非構造化データは、形式の自由度とデータの高速収集がメリットといえます。
構造定義されておらず、必要になった際に定義されることで、データの用途に合わせて柔軟に変更することが可能です。保存データも特定の形式に制限されず、上述のような画像、動画、音声などのデータをそれぞれに適した形式でデータベースに保存できます。
また、データを構造定義しないということは事前のデータ処理を省略できるため、データを簡単に素早く収集できます。
非構造化データのデメリット
一方で、非構造化データはデータサイエンスの専門知識が必要であることが最大のデメリットです。定義されず、形式も自由となると、専門知識を有さない状態でのデータ活用は困難です。データサイエンスや関連分野の専門知識を学習し、データの活用方法などを理解して初めて非構造化データの真価を発揮することができます。
3.半構造化データとは?
構造化データと非構造化データの中間に位置するのが「半構造化データ」です。Excelの表のように行と列で厳密に構造が定義されているわけではありませんが、テキストや画像のような完全に自由な形式でもありません。データの内容を理解するための「メタデータ」や「タグ」といった構造的な情報をデータ自体が持つという性質があります。このため「自己記述的データ」とも呼ばれます。半構造化データの代表例として、JSONやXMLなどが挙げられます。
半構造化データのメリット
最大のメリットは柔軟性の高さです。構造化データほど厳格なデータ定義が不要なため、後から項目を追加・変更することが容易です。これにより、Webサイトのアクセスログや、SNSの投稿、IoTデバイスから送信されるイベントデータなど、様々なアプリケーションから得られる多様なフォーマットのデータを柔軟に取り扱うことができます。ある程度の構造を持つため、機械的な処理がしやすい点も利点です。
半構造化データのデメリット
一方で、分析の際に一手間かかる点がデメリットです。通常、SQLのような単純なクエリ言語だけでは分析が完結しない場合があります。また、様々なフォーマットが混在する可能性があるため、組織として一貫したルールを定めないと、効果的なデータ管理が難しくなるケースも考えられます。
4.構造化・非構造化データの違い
上記のことから、構造化データと非構造化データの違いをまとめると以下の通りです。
構造化データ:固定長ファイル、Excel / CSV、ROB内のデータなど
非構造化データ:テキスト、音声、画像、動画、センサーログなど
5.非構造化データの活用はなぜ重要?難しい理由は?
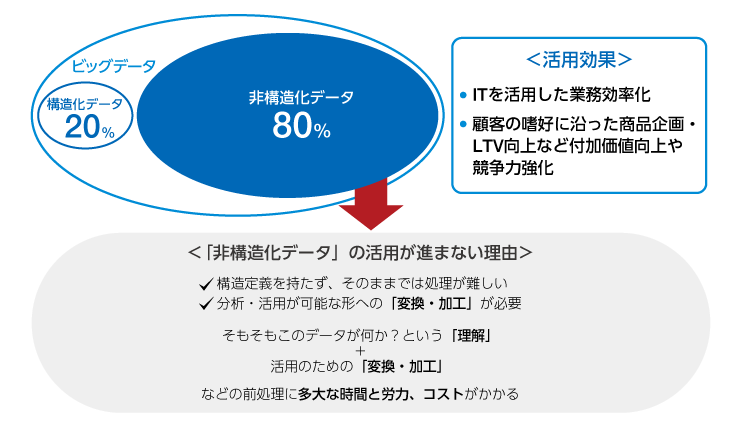
これら「構造化データ」と「非構造化データ」の総称が「ビッグデータ」と言えます。DXやIoT、ビジネスのグローバル化などに伴い企業の保有するデータは増大の一途をたどっています。中でも圧倒的にボリュームと種類が多いのが非構造化データであり、構造化データと非構造化データの比率は2:8と言われています。
非構造化データにはドキュメント/テキストデータ、画像/動画/音声データ、電子メールなど、日々の業務に関連するものが多い傾向です。さらに、研究/開発/設計データ、ログデータ/分析データ/映像コンテンツなど、昨今のトレンドに沿った情報も多く含まれます。そのため企業のデジタル戦略は、非構造化データ活用を避けては通れません。
非構造化データを活用することで、企業はITを活用した業務効率化に加え、顧客の嗜好に沿った商品企画やLTVといった付加価値向上や、競争力強化などの効果を期待できます。総務省の調査(情報通信白書 平成27年版)によれば「経営全般」、「企画、開発、マーケティング」、「生産、製造」、「物流、在庫管理」、「保守、メンテナンス」の5つのデータ活用領域のうち、「経営全般」、「企画、開発、マーケティング」でのデータ活用の割合が高く、またいずれかの領域でデータを活用している企業は約8割となっています。
しかし、前述の通り非構造化データは構造定義を持たず、そのままでは処理が難しいデータです。いくら高度なAI(機械学習、ディープラーニング)やBI(ビジネスインテリジェンス)を用いても、そもそも「そのデータは何か」「どんな関係性があるか」が認識できなければ、分析などに活用できません。そのため、非構造化データを分析・活用するためには、「変換・加工」が必要になります。
「データ分析は準備の時間が8割」と言われるほど、そもそもこのデータが何か?という「理解」、活用のための「変換・加工」などの前処理に多大な時間と労力、コストがかかります。企業の取得可能なデータの大半が非構造化データであるにも関わらず、なかなか活用が進まないのはこのためでした。
<非構造化データ活用が難しい理由>

CDP導入者1,030人に聞く!検討・導入・運用の理想と現実~企業のデータ活用の実態調査結果~
6.非構造化データを活用するには
「明確な構造定義を持たない」非構造化データですが、大きく2つに分類できます。
ここからは、それぞれをどのように「変換・加工」すれば活用できるのか解説します。
1|規則性があり、表形式の構造化データに変換して同様の手法で処理できるデータ
XMLはインターネットで広く利用され、3Dグラフィックスやソフトウェアの設定ファイル、RSSやAtomなどのフィードにも用いられています。JSONはXMLよりもさらにシンプルで処理が速く、最近ではWebサービスやスマホアプリのファイルの受け渡しなどによく利用されています。
XMLとJSONはどちらもテキスト形式のデータで、シンプル・軽量に扱えます。データ構造を自由に設計できる拡張性を持ち、共に書式と文法にルールがあります。XMLはデータ内に規則性に関する区切りがあり、JSONも一定のルールに従って記述されています。そのため、表形式の構造化データへ比較的容易に変換でき、非構造化データの中でも分析の対象にしやすいデータです。
2|規則性がなく、構造化データへの変換が困難、または変換できないデータ
非構造化データの中でもその特性から、管理も分析も難しいとされるデータです。近年では、「規則性がないデータから規則性を見つける」アプローチによる活用が進められています。
その手法の代表例はAI(機械学習、ディープラーニング)による「画像認識」「音声認識」「自然言語処理」などです。画像認識であれば「AIがあらかじめ学習した大量のデータパターンの中から、判定対象の画像の規則性を見つけ出す」、音声や自然言語処理、センサーデータでは「波形や文脈などの特徴から分類や区別、判断や予測を行うための規則性を抽出する」といった方法です。
ただし、AIに投入する以前に、大量に収集された非構造化データの中から分析に必要なデータをすばやく見つけ出すための各データの蓄積・更新の際に「タイトルや出所、ファイル形式などをメタデータとして一定のルールで付与する」といった、管理上の課題をクリアする必要があります。

CDP(プライベートDMP)基礎知識~導入成功ガイドブック~機能と役割、活用事例と導入成功のステップまで解説~
7.データ活用における「データレイク」と「DWH」とは
構造化データや非構造化データを活用する上で欠かせないのが、データを蓄積する基盤です。ここでは代表的な2つである「データレイク」と「DWH(データウェアハウス)」の違いと、その使い分けについて解説します。
●データレイク:あらゆる生データをそのまま貯める湖
データレイクは、構造化・非構造化を問わず、あらゆる形式の生データをそのままの形で一元的に保存するリポジトリです。将来的にどのような分析に使用するか決まっていなくても、価値がありそうなデータをまずは貯めておく、という目的で利用されます。加工されていない多様なデータを使用して、データサイエンティストなどが高度な分析を行う際の基盤となります。
●DWH:目的別に整理・加工されたデータの倉庫
DWH(データウェアハウス)は、組織の意思決定を支援するために、様々な業務システムから収集したデータを目的別に整理・統合して蓄積するデータベースです。DWHに保存されるのは、分析しやすいようにクレンジング・加工された構造化データが中心です。経営状況の可視化や定型的なレポーティングなど、ビジネスユーザーが迅速にデータを分析する用途に適しています。データレイクと連携し、必要なデータだけをDWHに格納する使い方も一般的です。
8.非構造化データの「適切な管理」という課題
このように規則性がなく、構造化データへの変換が困難な非構造化データの活用に向けた技術が進化している一方で、大きな課題として残るのが「適切な管理」という点です。以下、非構造化データを正しく活用するために必要な管理上のポイントを解説します。
1|データの保管・運用管理
非構造化データは構造化データと異なりデータ容量が大きく、データ単体で用途が異なります。そのため「どのように分類・保管するのか」という運用ポリシー、社内ルールの策定や従業員への教育が欠かせません。物理的には収集・生成されたデータを保管しておくための大規模なストレージが必要で、データ量が増加するに伴い拡張が求められます。
2|データの検索・更新性の維持
非構造化データは構造化データと異なりデータベースで扱うことが難しいため、ファイルのボリュームが増えれば増えるほど検索・更新性を維持することが困難です。非構造化データは日々業務で活用されるデータ群のため、「どこにあるのか」「どのファイルが最新なのか」「どのファイルのどの部分を、誰が更新したのか」などを把握する仕組みが必要といえます。
3|セキュリティ対策とガバナンス
非構造データは構造化データとは異なり、従業員が誰でも自由にファイルを作成・保存・編集できます。加えて、非構造化データには「機密情報」や顧客などの「個人情報」が含まれるケースも多く、セキュリティ対策およびガバナンスに細心の注意を払う必要があります。
9.まとめ
いかがでしょうか。これまで企業のデータ活用は、SCM・ERP・CRMシステムの刷新など、構造化データを主軸としたITプロジェクトが主流でした。しかし近年では、社内に膨大に存在する非構造化データの活用が注目され、実現するための技術やソリューション、プラットフォームの提供もICTベンダーを中心に活発化しています。この活発化に比例して、前述の管理問題が企業の重要課題として浮き彫りになってきています。
TOPPANは構造化・非構造化データに関わらずあらゆるデータをCDP(カスタマー・データ・プラットフォーム:顧客データを管理するプラットフォーム)で統合・管理し、AIを用いてマーケティング施策の精度を向上させるサービスを提供しています。さらに、企業のデータ利活用のために単なるツールの提供とプラットフォーム構築にとどまらず、目的に応じた導入から構築支援の各種コンサルティングや、デジタルマーケティングの人材リソースの提供などでも数多くの実績を誇ります。
非構造化データ活用についてご検討されている方は、ぜひお気軽にご相談ください。
10.その他構造化データに関するよくある質問
Q:構造化データの注意点はありますか?
A:構造が厳格であるため、初期設計を誤ると改変コストが高騰する恐れがあります。業務フローや追加機能を見据えて、余裕あるモデリング、設計書の随時更新体制などが求められます。
Q. スキーマを途中で変更したら過去データはどうなりますか?
A. 新旧スキーマを並存させる「スキーマバージョニング」や、CDP 側で項目を自動マッピングする方法があります。いずれにしても変更履歴を記録し、BI/MA ツール側にも連携ルールを伝播させることが重要です。
Q. 構造化データでプライバシー対策はどう行いますか?
A. ①ハッシュ化やトークン化で直接識別子を避ける ②データアクセス権限を項目レベルで制御 ③利用目的ごとの最小限項目のみ抽出 ④アクセスログ保管、などが基本です。
Q. 「ファーストパーティデータ重視」と構造化データの関係は?
A. 3rd パーティ Cookie 規制の進行に伴い、自社で直接取得した構造化データ(ファーストパーティ)を CDP に蓄積し、広告・販促・カスタマーサクセスへ活用する流れが主流です。構造化が進むほど分析精度が高まり、広告依存を減らせます。
Q. AI/機械学習は構造化データがなくても使えますか?
A. 可能ですが、モデル学習や特徴量生成の前段で「整理された構造化データ」があるほうが圧倒的に精度と開発スピードが向上します。そのため多くの企業はまず CDP で構造化 → AI 連携というステップを取っています。
Q. Excel や基幹 DB にある既存データもそのまま CDP に移せますか?
A. 形式が CSV や RDB であれば基本的に移行できます。ただし「カラム命名」「コード体系」「タイムスタンプ」などの標準化が必要です。移行ツール/ETL が自動補正する場合でも、ビジネスルールを事前に整理しておくと後工程が楽になります。

2026.01.08