<DATA CAMP 2019>
メディアビジネスの将来とテクノロジー
※所属企業名・部署名は2020年3月時点
| 登壇スピーカー 株式会社講談社 織田 順一 氏 株式会社白ヤギコーポレーション 渡辺 賢智 氏 ファシリテーター TOPPAN株式会社 後藤 達明 |
AI分野の高い技術力を生かし、コンテンツ配信を最適化
後藤 達明:「メディアビジネスの将来とテクノロジー」というテーマで、パネル形式でお話させていただきます。講談社の織田さん、白ヤギコーポレーションの渡辺さんから自己紹介をお願い致します。
織田氏:講談社の織田と申します。前職はコンサルティングファームにいまして、2010年より現職です。講談社ではスタートアップに投資をしたり、スタートアップと協業を進めながらデータの活用を進めたりしています。
渡辺氏:白ヤギコーポレーションの渡辺と申します。私もコンサルティングファームを経て、現職です。元々はPanasonicにおりましたので、メーカーのマインドを持っています。データ活用の課題を持つ企業が増えていたり、私自身もデータ収集や活用方法について考えていたりしたところ、良いアイデアが見つかったため起業しました。
後藤:私は企業様のデジタルマーケティングやイノベーションの支援をさせていただいています。今までは、企業固有のデータ基盤を整備するようなご支援が多かったのですが、今はデータ活用を行うためのエンジンをカスタムメイドで提供する機会が増えてきています。
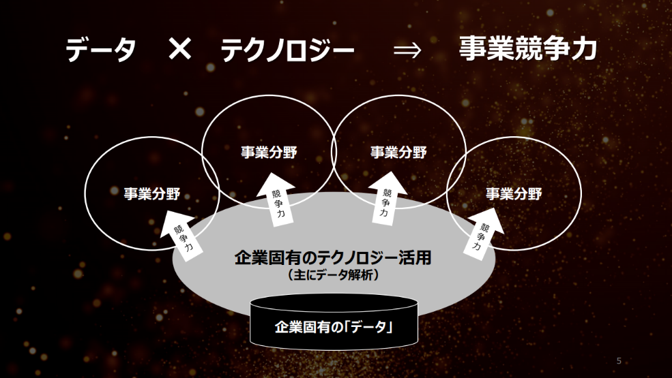
2017年1月に、講談社と白ヤギコーポレーションが資本業務提携すると発表されました。まさに、テクノロジーと固有のデータの組み合わせをされようとしています。この背景からお聞かせいただけますか。
織田氏:講談社は2016年11月に、白ヤギコーポレーションに出資しました。モニタリングしていたAIの会社はいくつかありましたが、白ヤギコーポレーションはその中でも、自然言語処理の分野で高い技術力があり、関心を持ちました。
渡辺氏:白ヤギコーポレーションは、2013年5月に創業しました。機械学習やディープラーニング、自然言語処理、ビッグデータ解析などを軸にしています。
例えば講談社であれば、小説や雑誌など膨大なコンテンツを持っています。当社は、これまでできなかったような、すべてのコンテンツを読み込んで、その内容によって分析をしたり、分類をしたりといったことを得意としています。
社は、これらの技術をベースにした「カメリオAPI」も提供しています。ネット上のさまざまなニュース、企業発表、官公庁発表情報などを取得し、検索・分類可能にするAPIで、CRMやSFAツールと連携し、業界情報の収集などにご活用いただけます。
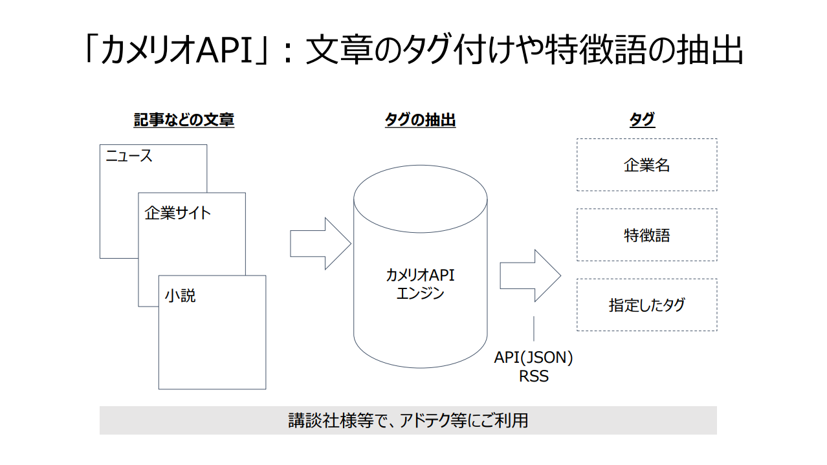
後藤:「カメリオAPI」は、大量の文書の中から特徴語を抽出できるAPIとのことですが、御社独自の強みはどのような点でしょうか。
渡辺氏:企業情報を収集したいという場合、例えば「パスコ」という航空測量の会社があります。一方で敷島製パンのブランド名も「パスコ」です。これまでの抽出では、航空測量のパスコの情報が欲しいのに、パンの記事ばかりが出てくる、といった問題が起こりがちでした。人間ならば簡単に両者を仕分けることができます。しかし、機械にはそれが難しいのです。
「カメリオAPI」は、そのような同名のものの抽出、仕分けも得意としています。
「オタク」+「アド」のインターネット広告プラットフォームを提供
後藤:講談社との提携では、白ヤギコーポレーションのテクノロジーをどのように商品やサービスの刷新に生かしているのでしょうか。
講談社では2019年10月、インターネット広告プラットフォーム「OTAKAD(オタカド)」の提供を開始した、というリリースを出されましたね。
織田氏:「OTAKAD」は「オタク+アド」の合成語です。皆さんそれぞれ何か趣味、こだわりを持っていて、その「オタク性」に応じて情報を集めていると思います。その「オタク性」に合わせてダイレクトにユーザーにリーチできるのが「OTAKAD」です。

通常の広告では、何か自社製品の広告を出したいときに「20代女性、住んでいるところはここ、収入はこれぐらい」など、属性によるセグメンテーションをすることが多かったと思います。しかし、売りたい製品は20代女性しか買わないわけではないし、住んでいるところを限定しているわけでもない。ただ製品を売りたいだけなのに、回りくどいし効率が悪いと感じていました。
当社にはさまざまなメディアがあります。メディアは、コンテンツ、文章の集まりです。ならば、それを解析すると「ユーザーが何に興味があるか」がわかるのではないか。さらに、白ヤギコーポレーションの力も借りながら演算していくと、「この人はどんな『オタク性』があるか」がわかるのではないか。そして、その人たちに製品を紹介すれば、今までよりも買ってもらえる比率が高くなるのではないか、という考えのもと、つくった仕組みが「OTAKAD」です。
後藤:ペルソナの部分は、どのように作られているのですか。
織田氏:そこが当社の特長です。「こういう記事や単語に興味があるから、こういうオタクだろう」というのは、テクノロジーというよりも割と文系っぽい領域、当社なら編集者のノウハウの領域だと思います。
例えば、「ミーハートレンダーガール」というのはこういう人だよ、ということを事前にAIに教えます。すると、AIがデータを探し当てて「最終的にこの人です」、ということがわかるような仕組みを作っています。
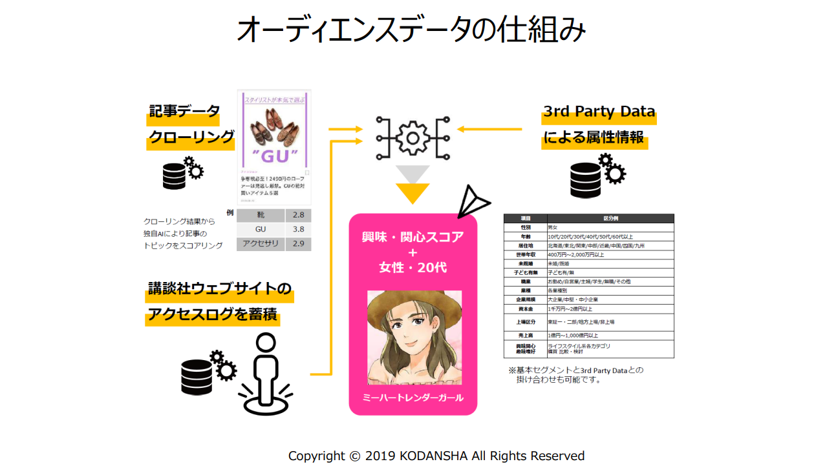
後藤:そのセグメントがいくつもあるわけですね。
織田氏:現在は男女合わせて20ほど定義しています。例えば「アンチエイジンガー」などは、属性によるセグメンテーションでは定義が難しかったものです。アンチエイジングを意識するのは30代からなのか。50代はいるのか、いないのか。20代もいるかもしれない。いずれにしても女性だよね、という感じでした。
それに対して「OTAKAD」では、実際に見た記事を元に、「この人はアンチエイジンガーっぽい」ということをAIとデータで当てにいく、という作業をしています。
後藤:渡辺さんは、このような人の仮説とAIの処理を組み合わせたサービス設計について、どんな印象を持ちましたか。
渡辺氏:当社にとっても新しい経験でした。一般的に、AIは広告のクリック率を高めるといったように、特定のKPIを決めてそれを最大化させることは得意です。ところが今回は、例えばクラスターについても、統計的なデータからクラスターを切り出すのではなく、まず編集の方の「アンチエイジンガー」というクラスターがあるんじゃないか、という仮説を元に作るのです。
そういった人間のアートの部分と、大量のデータを処理して解を出していくというAIの部分、これをうまく組み合わせることができたと考えています。

GDPRやITPなど個人情報、プライバシーの保護の潮流
後藤:最後に「データ環境とメディアビジネスの将来」について伺いたいと思います。特に、GDPRやITPなど個人情報、プライバシーの保護などの潮流について、お二人はどのようにお考えでしょうか。
織田氏:各国の法規制に準拠することはもちろん大前提ですが、あまり各論に入ると迷子になってしまう論点だと思います。どの国のどの規則はこうなる、プラットフォーマーが規約を変更する、といった動向は日々変化しますが、少し引いて見れば、「個人データは企業のものではなく個人のものだ」という流れ自体は変わらない。その点では結局、個人から評価されて信頼を得たサービスが勝ち残る。作り手側からすれば、「良いものを作ればいい」という時代が来ているわけで、それは望ましいことだと思います。
渡辺氏:個人情報については、データを処理する上で、「どこまで、何をやっていいのか」という判断は悩ましいところです。当社としては、講談社のように、データを実際に使う企業がどのようなポリシーを持ってどう使うのかをしっかりと把握した上で、当社のシステムや仕組みに反映させていくことを考えています。
【参考】
2021.12.10




